Fundamentals of RAG Architecture

How RAG Works: The Three Primary Steps
- 1 Retrieve — Relevant information is fetched from a data store based on the user's query.
- 2 Augment — The query is combined with the retrieved content to form an enriched prompt.
- 3 Generate — A response is produced that is grounded in the external data rather than parametric memory alone.
RAG Architecture Variants
| Variant | Data Source | Key Characteristic |
|---|---|---|
| Standard RAG | Flat document text | Semantic similarity search over a vector store |
| GraphRAG | Knowledge graph (nodes, triplets, paths, subgraphs) | Captures deep relational knowledge that semantic similarity alone may miss |
| Agentic RAG | Multiple heterogeneous sources | LLM decomposes complex inputs into parallel subqueries for broader, more relevant results |
GraphRAG: The Three Formal Stages

- ▸ Graph-Based Indexing — Entities, relationships, and facts are extracted from source documents and stored as a structured knowledge graph.
- ▸ Graph-Guided Retrieval — Queries traverse the graph to surface related nodes, paths, and subgraphs beyond what a flat vector search would return.
- ▸ Graph-Enhanced Generation — The LLM synthesises a response using the rich, structured context recovered from the graph.
RAG Orchestration: Indexing and Retrieval Strategies
Retrieval is not a single operation — it is a pipeline decision. The query type, data topology, and acceptable latency budget together determine which retrieval paradigm is appropriate. A poorly chosen retrieval strategy is one of the most common causes of RAG underperformance in production: a system that retrieves too little misses critical context; one that retrieves too broadly dilutes the generation prompt with noise that actively degrades answer quality. RAG systems address this by selecting from three distinct retrieval paradigms, each with different latency, cost, and coherence characteristics.
Retrieval Paradigms
- ▸ Once Retrieval — All pertinent information is gathered in a single query operation. Simple and low-latency, best suited to well-scoped questions.
- ▸ Iterative Retrieval — Further searches are conducted based on previously retrieved information. Can be adaptive (the LLM decides when enough context has been gathered) or non-adaptive (a fixed sequence of queries).
- ▸ Multi-Stage Retrieval — Retrieval is split into linear stages, each potentially using a different method — for example, a keyword search followed by a vector search — to progressively refine results.
Vector Index Algorithms

| Index Type | Accuracy | Best For |
|---|---|---|
| flat | 100% (exact match) | Fewer than 1,000 vectors; testing environments |
| quantizedFlat | ~95% | 1K – 100K vectors |
| diskANN | ~95% | 100K+ vectors; high-performance production workloads |
Generation Orchestration and Prompt Design

SELF-RAG: Reflection Tokens
Architectures like SELF-RAG train models to output special reflection tokens that allow the model to critique its own retrieved context and generation — ensuring it only surfaces highly supported facts.
- ▸ Retrieve — Signals that additional retrieval is needed before generation can continue.
- ▸ ISREL — Asserts whether the retrieved passage is relevant to the query.
- ▸ ISSUP — Asserts whether the generated output is supported by the retrieved passage.
- ▸ ISUSE — Rates the overall utility of the response to the user's query.
Prompt Engineering for Text-to-SQL RAG

Security recommendation — Text-to-SQL pipelines should always connect to the database through a read-only user account or expose only read-only database views to the LLM. Even with prompt-level DML restrictions, a compromised or manipulated prompt could attempt destructive queries. Enforcing read-only access at the database layer is the only reliable safeguard.
<|start_header_id|>user<|start_header_id|> Generate a SQL query to answer this question: '{question}' ### Instructions - Given an input question, create a syntactically correct query to run. - Never query for all the columns from a specific table; only ask for the relevant columns. - Do not add ORDER BY in the query unless the user has explicitly asked for ordered results. - If you cannot answer the question with the available database schema, return 'I do not know.' - DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP, etc.) to the database. DDL statements: {Retrieved_Table_Schema_Information} <|eot_id|><|start_header_id|>assistant<|start_header_id|>
RAG Validation, Validator Agents, and Evaluation Gates
Core Evaluation Metrics: The RAG Triad
The industry standard for evaluating RAG pipeline quality has converged on three core pillars known as the RAG Triad. What makes these metrics particularly powerful is that they are reference-free — they do not require a pre-labelled ground-truth dataset to compute, which means they can be applied continuously in production, not just during offline test runs. Frameworks such as RAGAS, TruLens, and DeepEval implement the triad using an LLM-as-a-judge approach: a separate model evaluates the pipeline's outputs against the retrieved context and the original question, producing scores that expose exactly which stage of the pipeline is degrading quality. This separation of concerns — one model generating, another evaluating — is what gives the triad its diagnostic precision.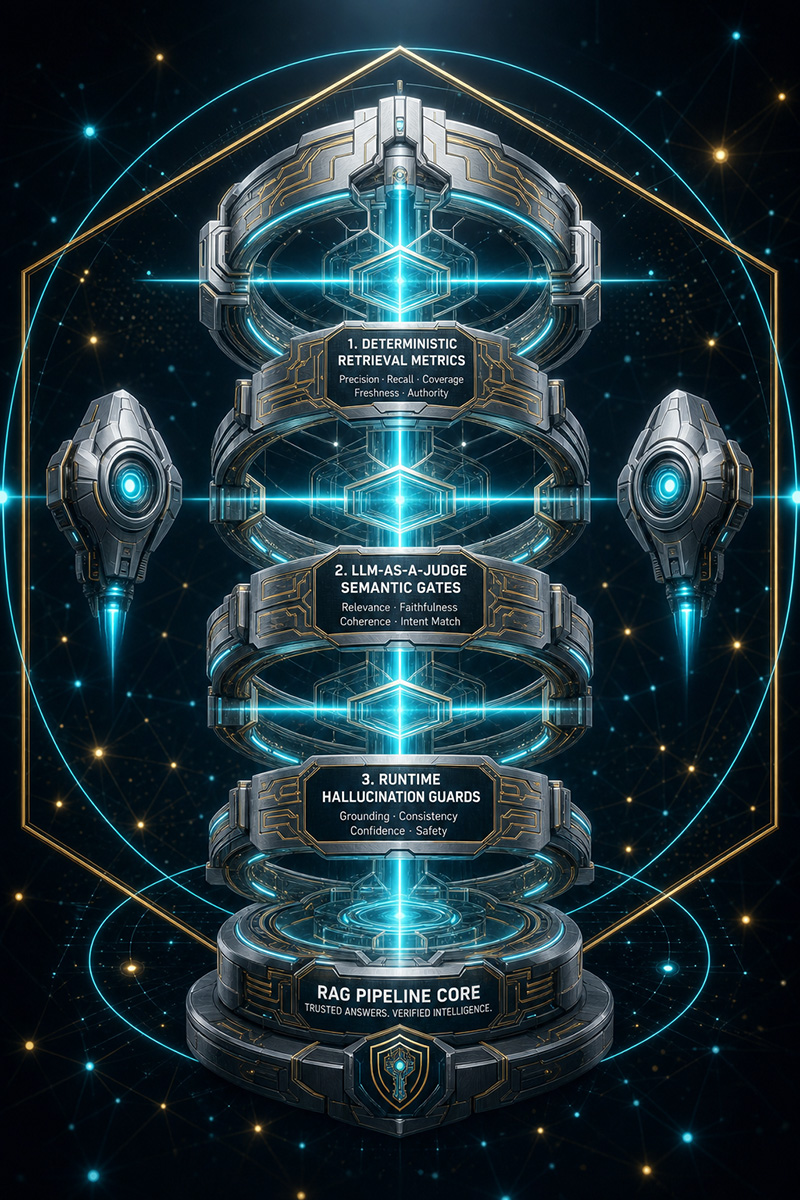
- ▸ Context Relevance & Precision — Measures whether retrieved documents are focused and genuinely relevant to the query, surfacing any retrieval noise.
- ▸ Faithfulness (Groundedness) — Evaluates whether the generated answer is factually grounded in the retrieved documents, ensuring the model isn't hallucinating claims outside the provided evidence.
- ▸ Answer Relevancy — Assesses whether the response directly addresses the user's original question, penalising answers that are technically truthful but off-topic.
Evaluation Frameworks
| Framework | Best Suited For | Core Integration Feature |
|---|---|---|
| RAGAS | Fast, reference-free RAG evaluation | Lightweight Python setup focused strictly on the RAG pipeline |
| TruLens | Unified evaluation and tracing | OpenTelemetry-based span tracing to isolate where a multi-hop trace fails |
| DeepEval | CI/CD pipeline maturity | Native Pytest integration to treat evaluations as pre-deployment quality gates |
Validator Agents and Role Separation

"In complex Agent chains, one bad output can cause a cascade of errors."
Validation Gates and Audited Handoffs

- 1 Prepare — The sending agent packages its outputs alongside provenance metadata: timestamps, hashes, and source citations.
- 2 Validate — The gate executes deterministic entry checks: PII detection, format validity, and hallucination markers.
- 3 Approve — The decision is recorded. A failed gate blocks the handoff and escalates the error.
- 4 Commit — Only approved outputs advance to state-changing operations.
The following is a deliberately simplified example to illustrate the core decision structure. A production implementation would extend this with async execution, structured logging, distributed tracing, and integration with your agent orchestration framework.
public enum GateAction { Pass, Warn, Block } public record GateResult(GateAction Action, IReadOnlyList<string> Issues, bool GateOpen); public static GateResult ValidationGate(string agentOutput, int step) { // Applies a 'Logic Lock' to intercept and audit LLM outputs before the next step. var issues = new List<string>(); var gateOpen = true; // 1. Deterministic format & length checks if (step > 0 && agentOutput.Trim().Length < 20) { issues.Add("Output too short for chain continuation."); gateOpen = false; } // 2. Hallucination marker detection string[] uncertaintyMarkers = ["i think", "probably", "might be"]; var lower = agentOutput.ToLowerInvariant(); if (uncertaintyMarkers.Any(m => lower.Contains(m))) issues.Add("Uncertainty markers detected — potential hallucination."); // 3. Decision routing var action = !gateOpen ? GateAction.Block : issues.Count > 0 ? GateAction.Warn : GateAction.Pass; return new GateResult(action, issues, gateOpen); }
By treating every step as a trust boundary, organisations transition from a brittle fail-open paradigm to a secure fail-stop architecture — ensuring that RAG and agentic workflows can be safely deployed into production.
Advanced GraphRAG Architecture for Enterprise Scale
The GraphRAG Enterprise Engine
- 1 Extraction — The input corpus is sliced into analysable text units. All entities, relationships, and key claims are extracted from each unit.
- 2 Hierarchical Clustering — Using techniques like the Leiden algorithm, interconnected nodes are grouped into communities and organised into a graph hierarchy.
- 3 Community Summarisation — Bottom-up summaries are generated for each community, giving the LLM a holistic understanding of the dataset's overall topology before a user ever asks a question.
Advanced Enterprise Query Execution
When reasoning over private enterprise datasets, GraphRAG provides three specialised search modes that balance computational cost with answer quality.
| Mode | Optimised For | Mechanism |
|---|---|---|
| Local Search | Targeted, highly specific questions | Vectorises the query to find semantically related entities, retrieving connected nodes, relations, and community reports |
| Global Search | Broad, dataset-wide queries | Retrieves community reports at a target hierarchy level and applies Map-Reduce to synthesise a comprehensive overview |
| DRIFT Search | Complex enterprise tasks requiring broad fact coverage | Combines local and global methods — community insights refine local queries into detailed follow-up questions for richer retrieval |
Orchestration and Infrastructure with Microsoft Foundry
Deploying multi-agent GraphRAG systems at enterprise scale requires unified, managed infrastructure — not ad-hoc collections of scripts wired together with environment variables. Microsoft Azure AI Foundry acts as the centralised control plane for this infrastructure, providing a single Azure management namespace that spans agent definitions, deployed LLMs, tool registrations, connection secrets, and evaluation pipelines. Rather than each team maintaining their own agent scaffolding, Foundry enforces consistent deployment contracts, versioned agent configurations, and centralised credential management across the entire AI estate. This uniformity is what makes enterprise-scale orchestration governable: every agent, regardless of which team built it or which model it targets, is visible, auditable, and controllable from a single operational surface.
Infrastructure uniformity alone does not solve the performance problem. At enterprise query volumes, retrieval latency compounds across every agent hop in a chain — a 200ms vector query that is acceptable in isolation becomes a multi-second bottleneck when repeated across ten pipeline steps. Enterprises deploying Foundry-based GraphRAG at scale typically back their retrieval layer with Azure Cosmos DB for this reason. By integrating Microsoft Research's DiskANN approximate nearest-neighbour algorithms directly into its storage engine, Cosmos DB eliminates the need for a separate standalone vector database while delivering sub-20ms latency for vector queries at production scale. Critically, it supports true hybrid search — combining dense vector similarity, BM25 full-text matching, and structured metadata filters in a single query — without round-tripping across multiple services. Operational data and retrieval data coexist in the same store, removing an entire class of synchronisation and consistency failure modes that plague architectures that split vector and document stores.
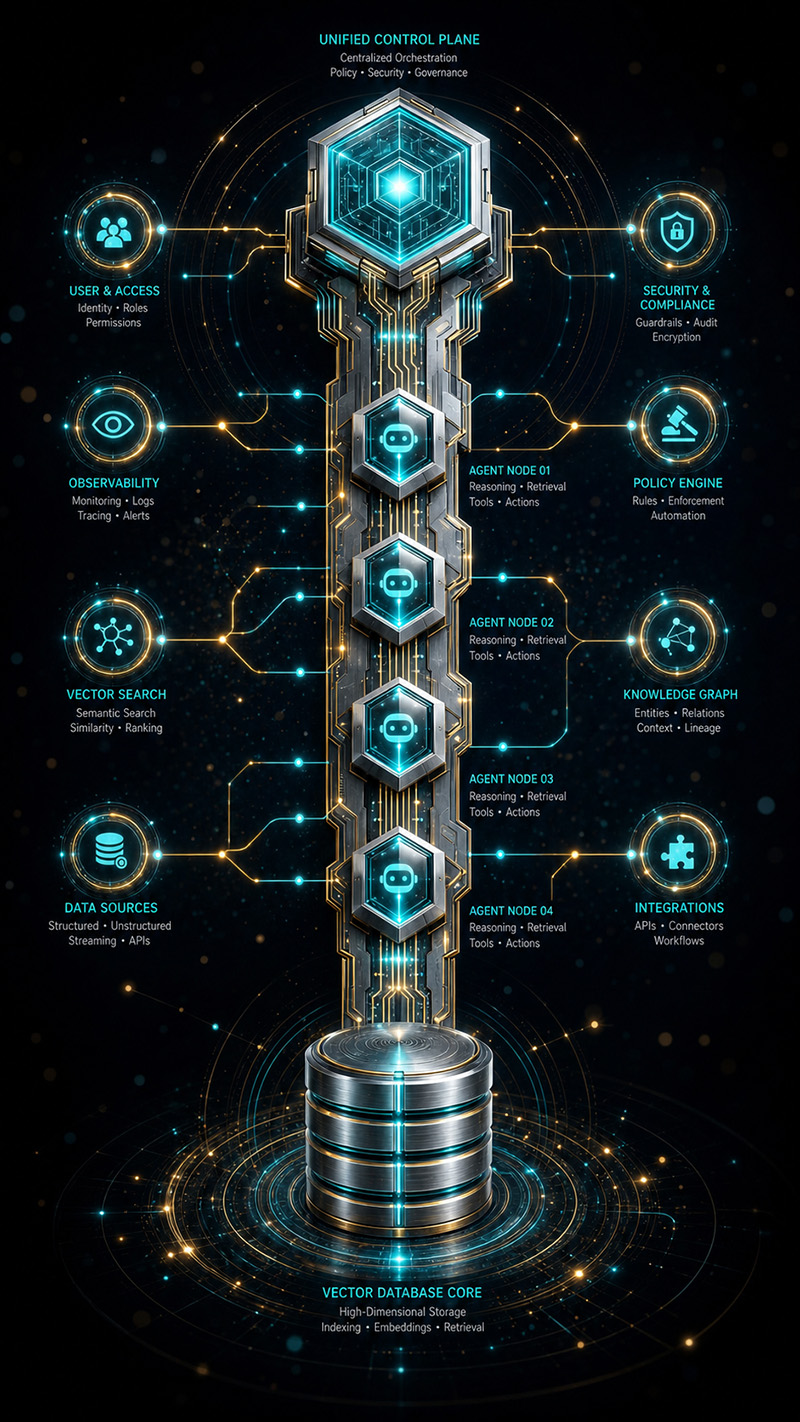
Enterprise Governance, Security, and MLOps
- ▸ Security and Access Control — Foundry components are deployed within isolated Virtual Networks via Azure Private Link with end-to-end encryption. Microsoft Entra ID enforces Role-Based Access Control (RBAC) at the document level, ensuring the AI only retrieves and serves data the specific user is legally and organisationally permitted to see.
- ▸ Continuous Observability — The Foundry Control Plane provides real-time dashboards tracking agent runs, throughput, latency, token consumption, and error rates out of the box.
- ▸ Content Safety and Guardrails — Built-in content safety filters actively monitor and block policy violations, toxicity, and prompt injection attacks in real-time, protecting the enterprise brand and preventing data leakage.
By combining the deep reasoning capabilities of GraphRAG with the scalable, secure, and observable infrastructure of Microsoft Foundry, organisations can safely automate business processes and unlock the full potential of their proprietary data at scale.